Data
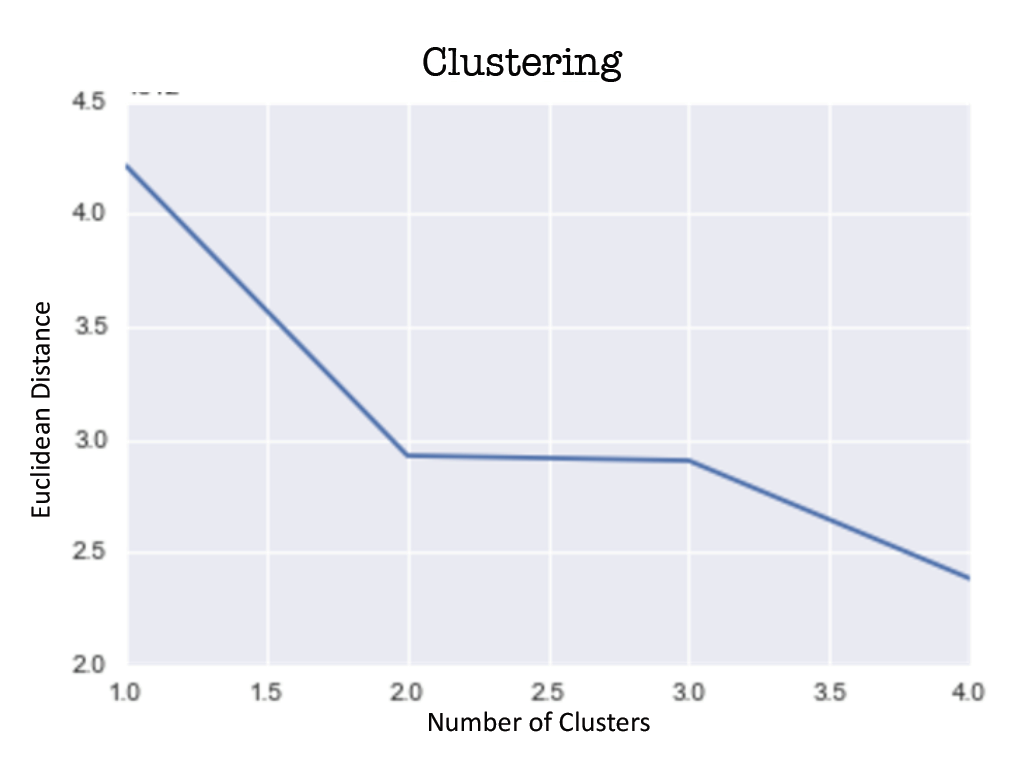
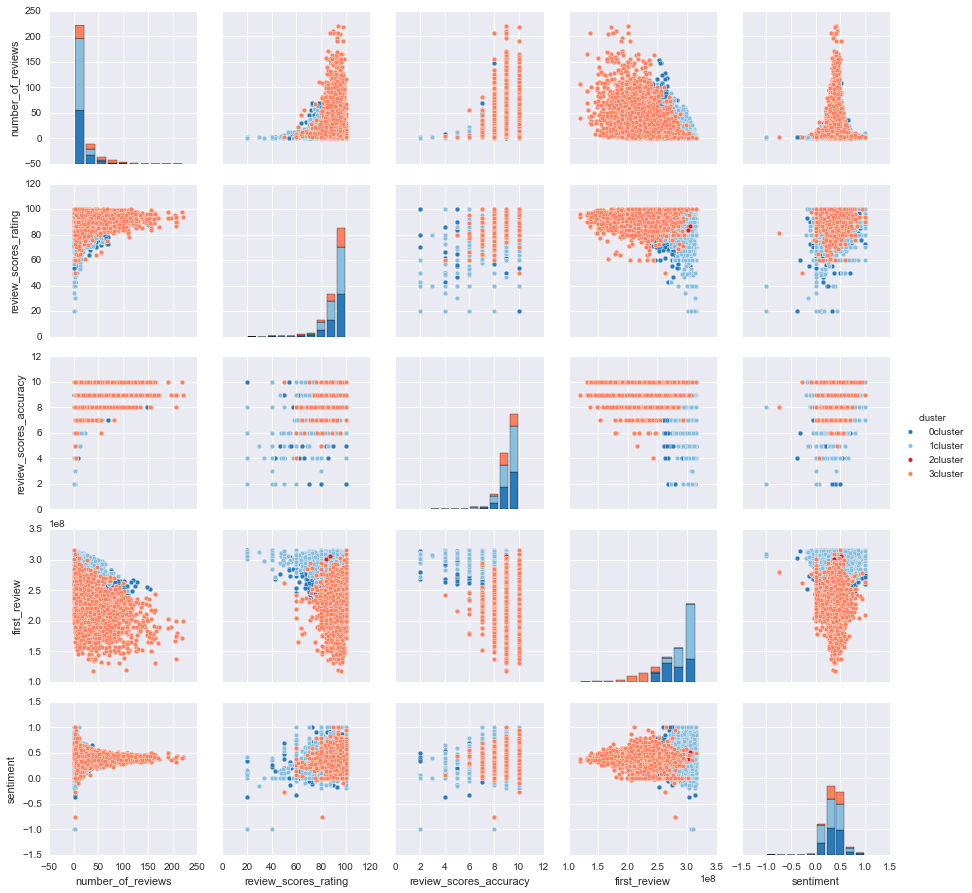
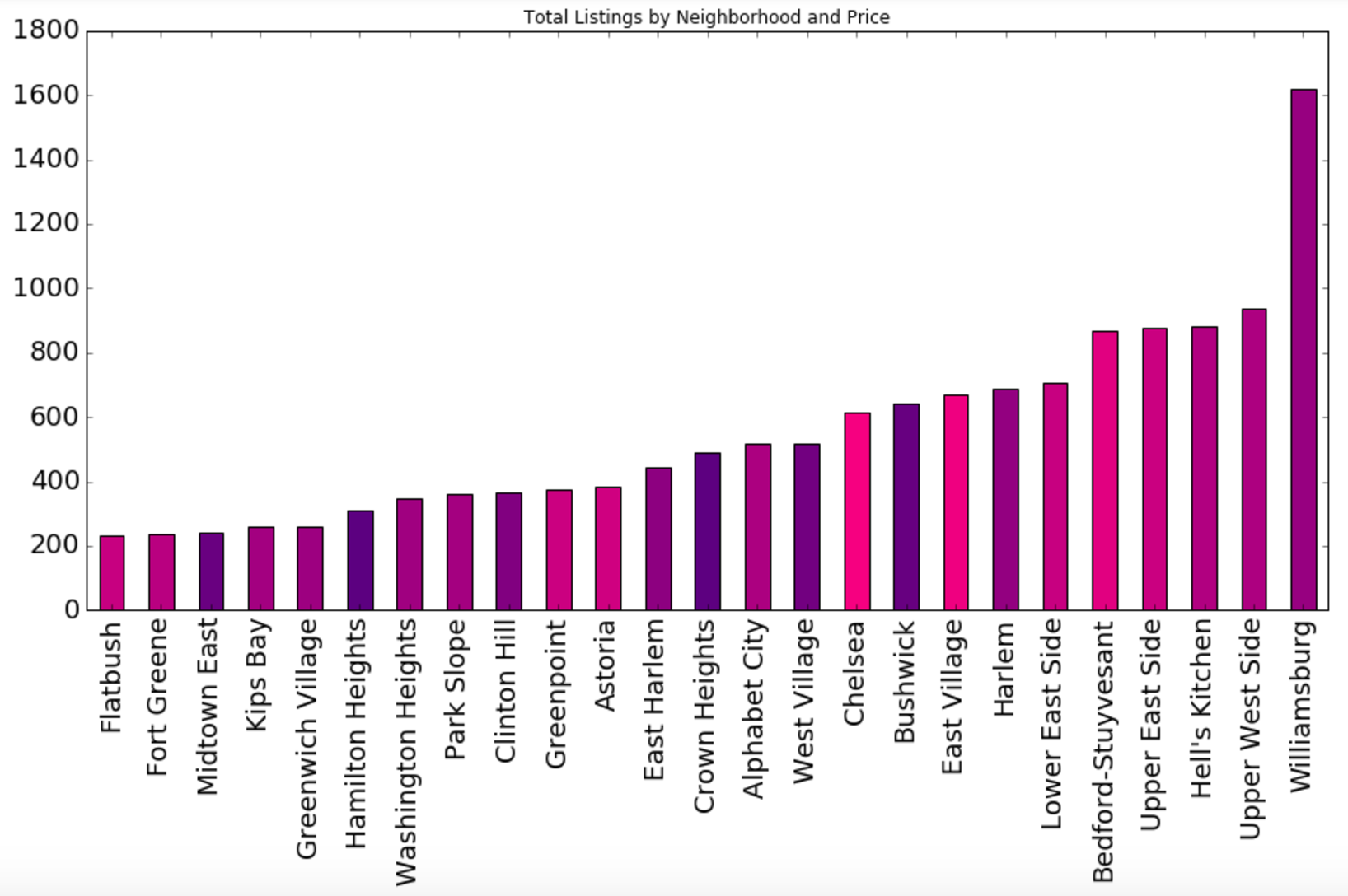
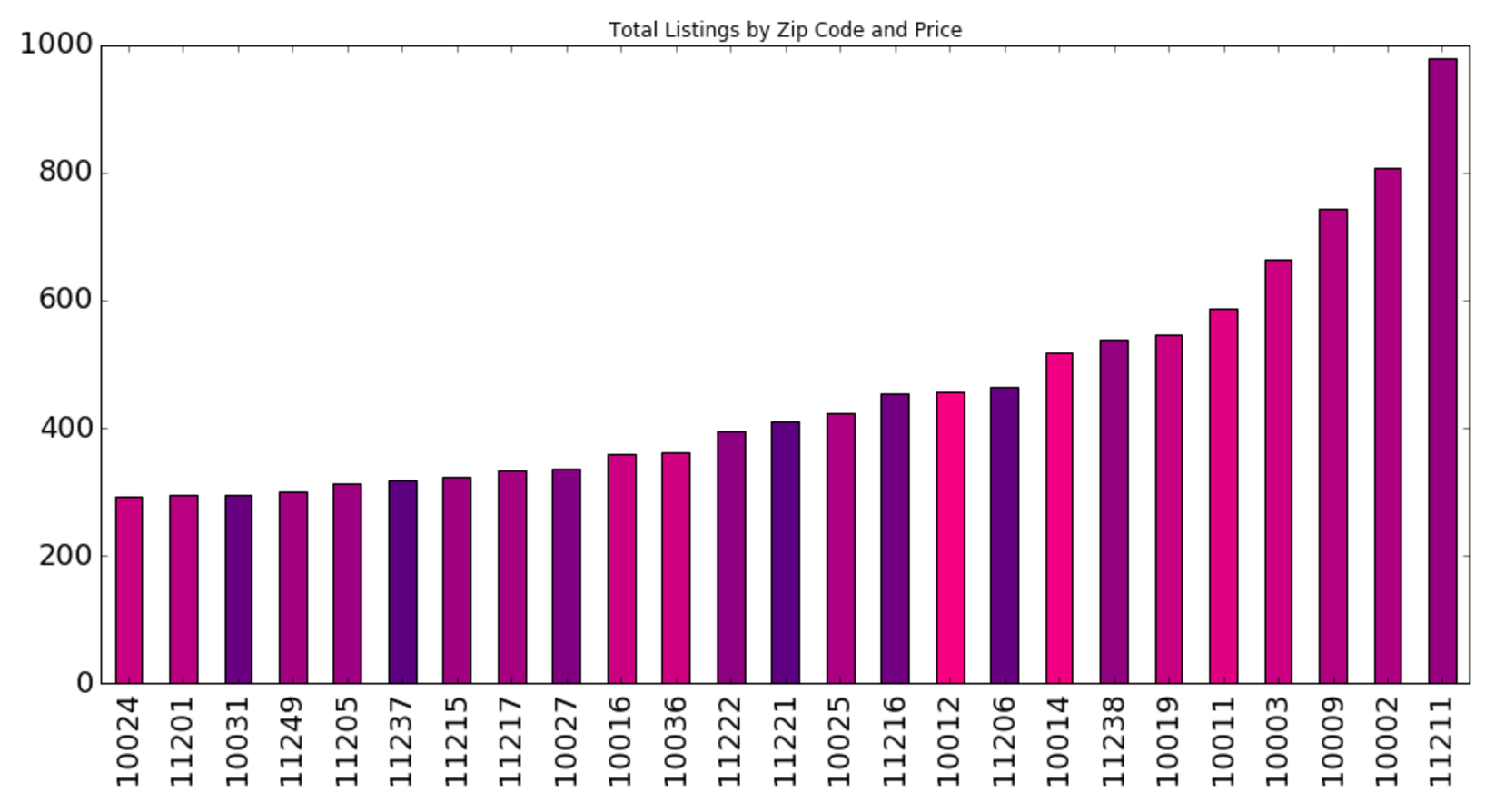
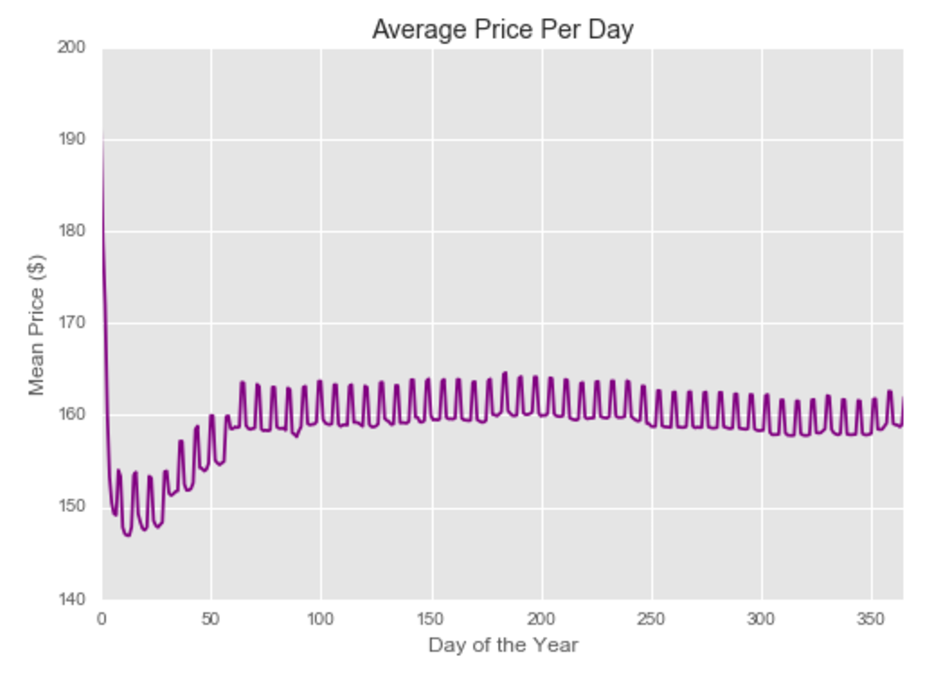
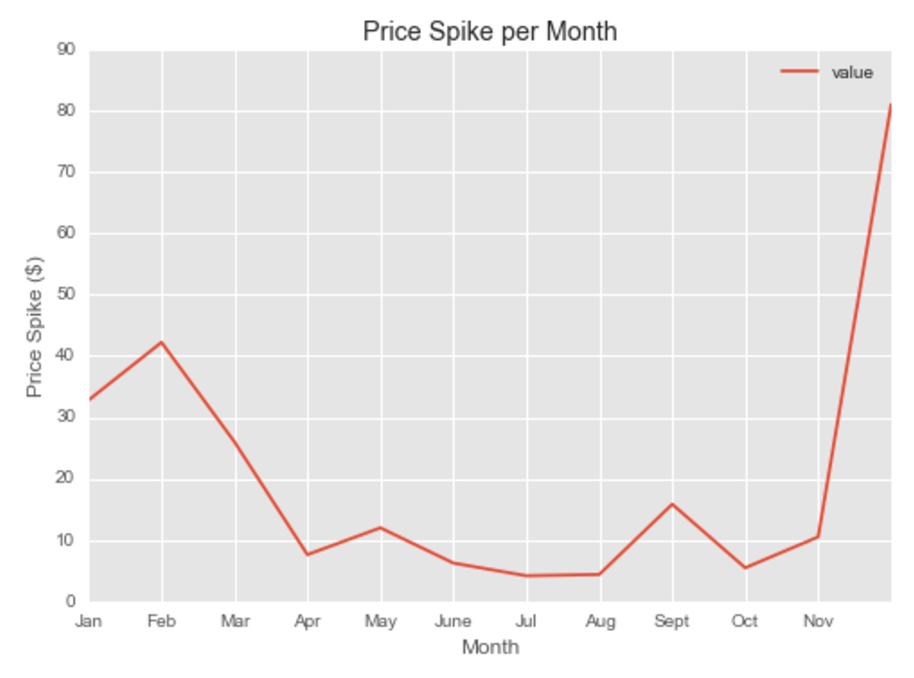
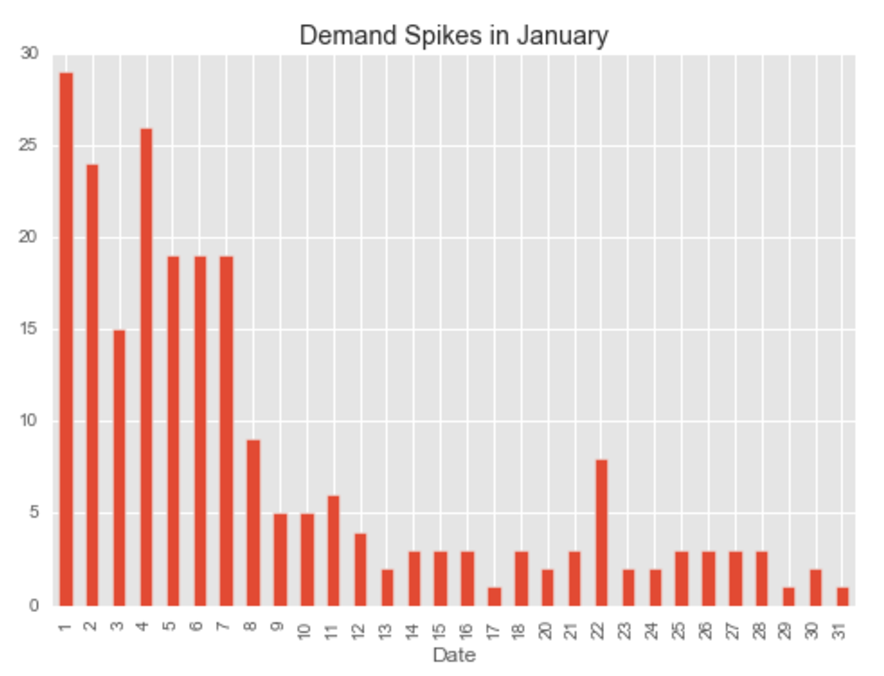
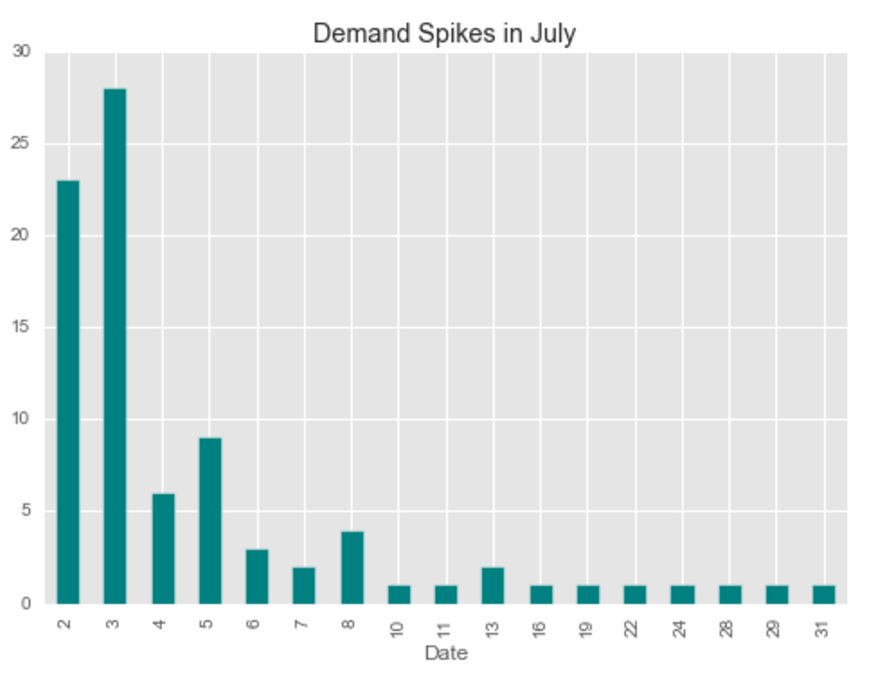
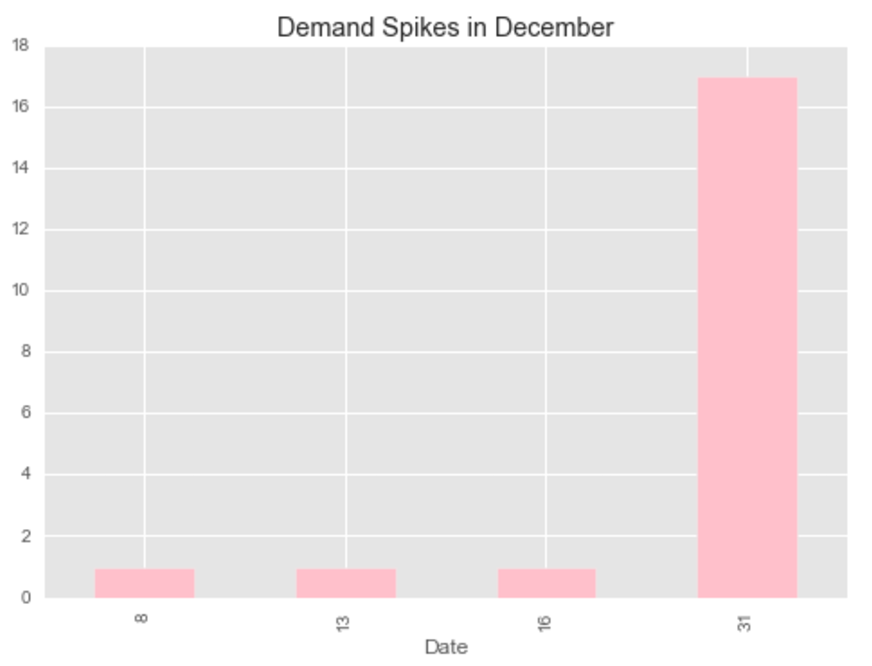
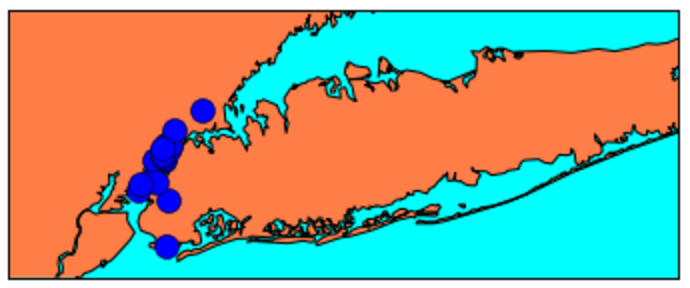
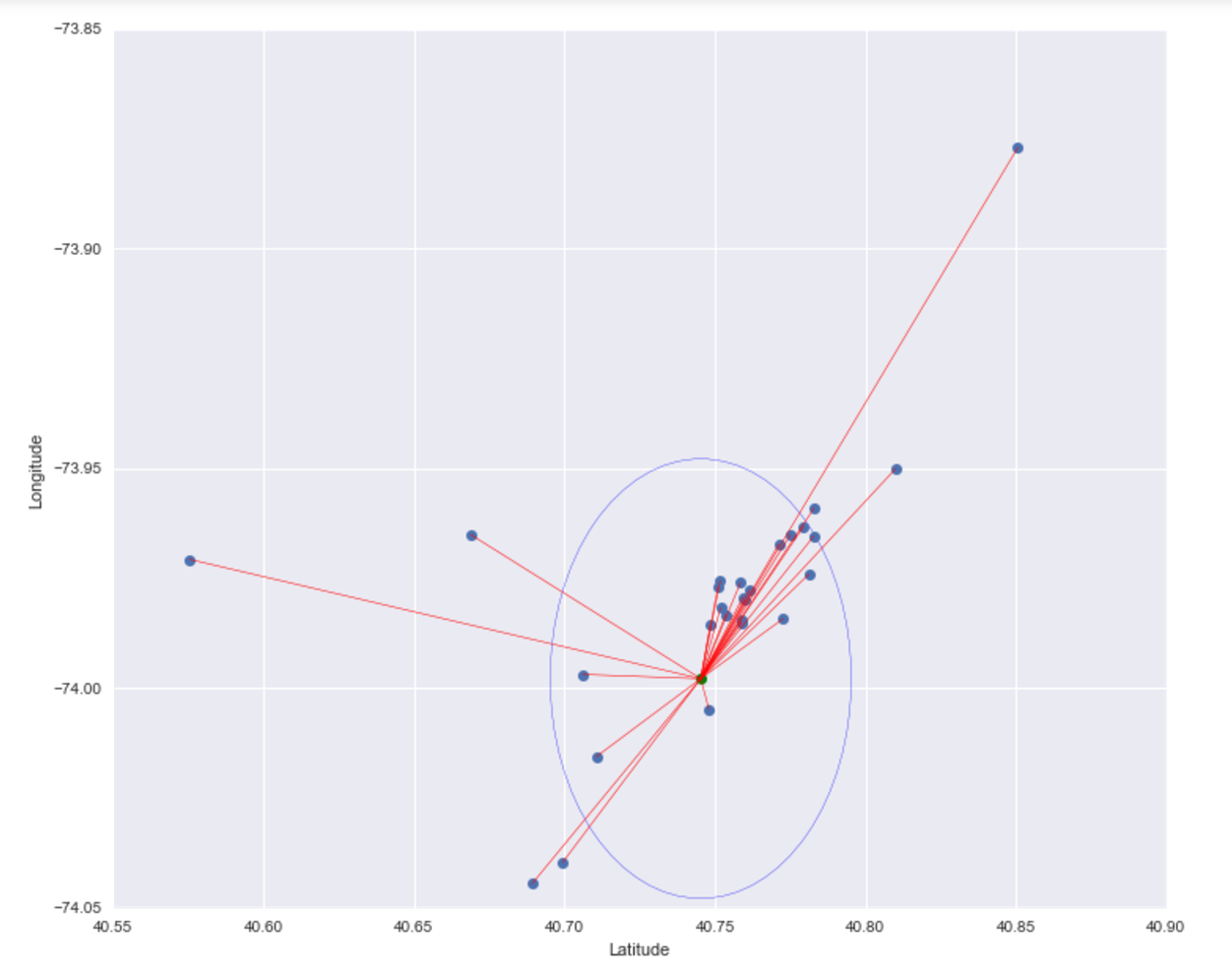
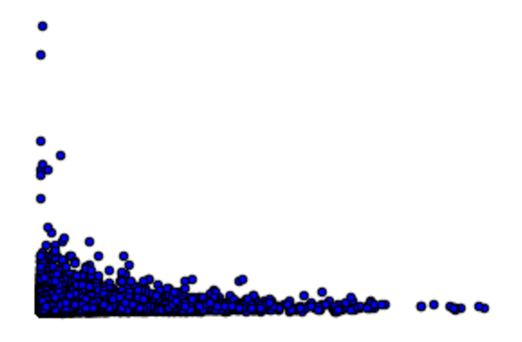
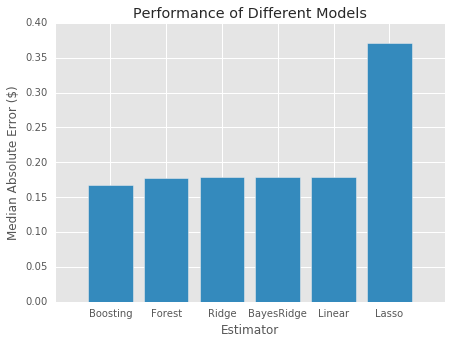
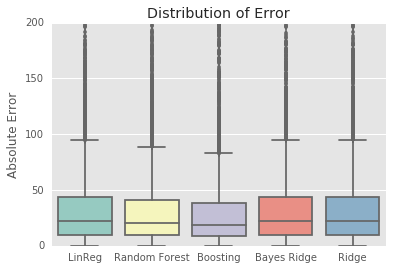
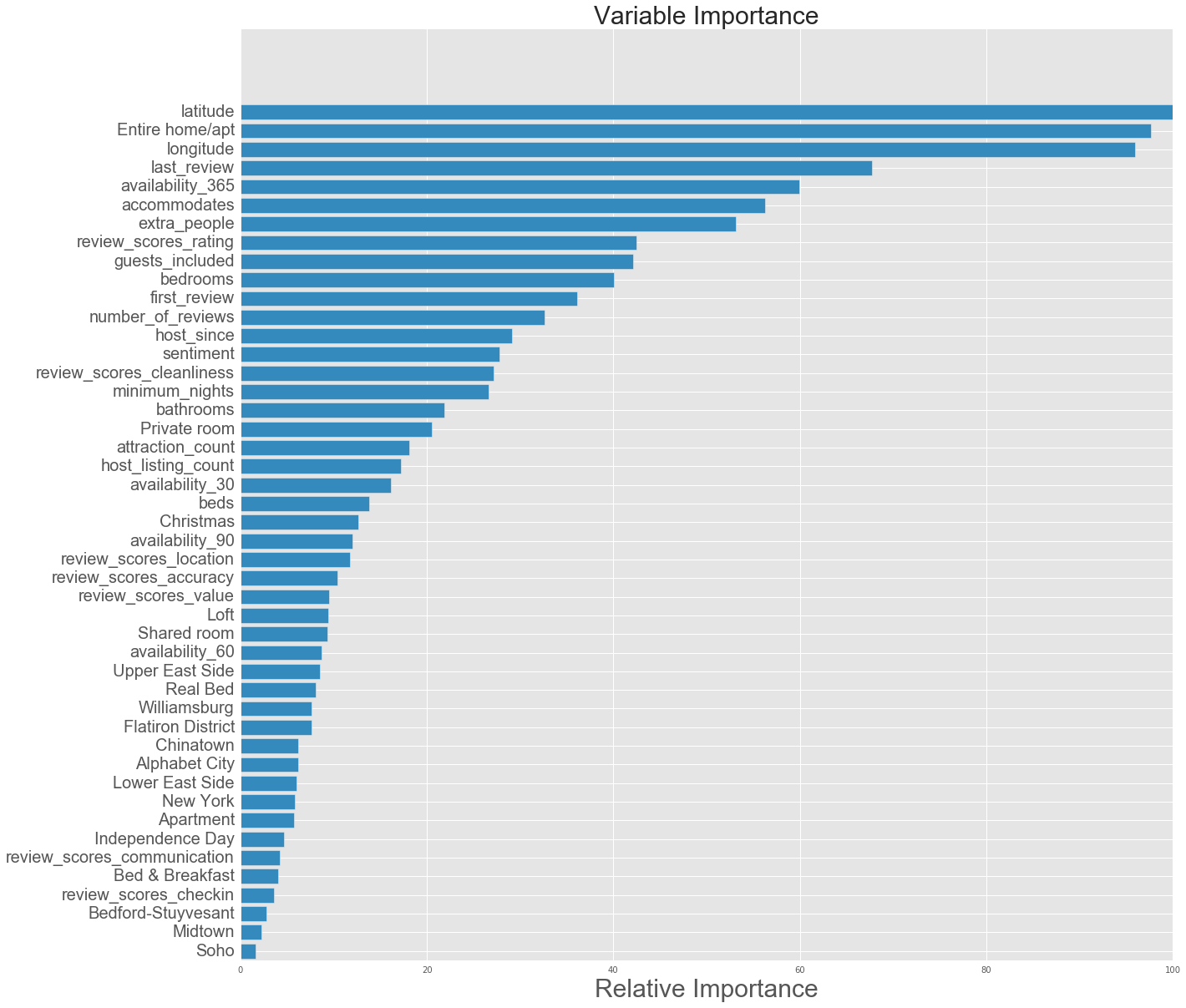
Our primary dataset for this project came from data.BetaNYC, an open source website aimed at improving New York City through civic technology and government transparency. Our dataset contains thousands of New York Airbnb listings and accompanying information about location, amenities, and price. Our secondary dataset contains the prices of listings every day of the year. We show initial observations of the dataset here.